Как искусственный интеллект научился распознавать больше объектов, чем видит

Иллюстрация: www.gettyimages.com
Ребенку достаточно один раз увидеть кошку, чтобы научиться распознавать кошек на всю жизнь. Искусственному интеллекту нужны тысячи изображений — этим процесс обучения ИИ отличается от человеческого. Необходимость обрабатывать огромные массивы данных, делает технологию дорогой с точки зрения вычислений.
Новый метод способен обучать ИИ, используя «меньше одной фотографии», как это называют ученые из университета Уотерлу в Онтарио (Канада). Иными словами, модель сможет различать больше объектов, чем количество примеров, на которых ее тренировали.
Исследователи продемонстрировали эту идею, экспериментируя с набором данных MNIST. Он содержит 60 тысяч обучающих изображений рукописных цифр от 0 до 9-ти и часто используется для проверки компьютерного видения.
Ученые вдохновились статьей коллег из Массачусетского технологического института, которые писали о методе «дистилляции» наборов данных и сжали 60 тысяч снимков MNIST до десяти, то есть, собственно, до цифр 0-9. Это были не просто выбранные из массива фотографии, а тщательно спроектированные изображения, которые содержали ту же информацию, но более сжато.
Экспериментаторы из Уотерлу решили: почему бы не уменьшить количество изображений до пяти? Человеку необязательно видеть единорога, чтобы научиться его распознавать: ему достаточно знать, как выглядят лошадь и носорог. Точно также и модель может учиться на снимках, где смешаны сразу несколько цифр.
Для этого используются так называемые гибридные или «мягкие» метки. То есть, ИИ видит цифру 3 и понимает, что она похожа на 8, но не 7 или 4. Поэтому он заявляет не «это цифра 3», а «это изображение на 60% – 3, на 30% – 8 и на 10% – 0».

.

Проверив этот метод на наборе MNIST, ученые задумались, как далеко может привести эта идея. Теоретически даже два изображения могут кодировать любое количество категорий — тысячу или даже миллион. Этот подход решили проверить на одном из простейших алгоритмов машинного обучения — kNN.
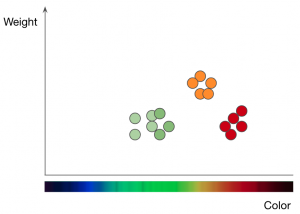
Суть kNN такова:
если вы хотите научить модель различать яблоки и апельсины, вы должны задать их основные характеристики, например, цвет и вес.
Затем вы вводите точку x— цвет и y — вес, а алгоритм отображает все точки на двухмерной диаграмме
и проводит границу между яблоками и апельсинами.
В дальнейшем модель решает, к какому фрукту относятся все новые точки-объекты.
Для своего эксперимента ученые создали серию крошечных наборов данных и продумали гибкие метки. В итоге им удалось получить график с большим количеством типов, чем было изначальных точек. Если соотнести этот пример с фруктами, то можно сказать, что смогли обучить модель различать яблоки, апельсины, груши и бананы, демонстрируя изображения только двух из них.
.
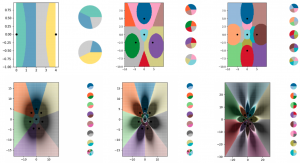
Такой подход позволит использовать меньшее количество данных, то есть сэкономить на расчетах, что сделает машинное обучение доступным для большего числа компаний. Кроме того, это увеличит конфиденциальность, ведь сейчас для обучения нередко используются изображения и данные реальных людей.
Выделите текст и нажмите Ctrl + Enter





